
Executing Signals And Responses In A Continued Process Verification Program
By Peiyi Ko, Ph.D., founder and consultant, KoCreation Design LLC

Part 1 of this series provided an overview of continued process verification (CPV) and how it is key to setting the foundation for continuous improvement in pharmaceutical manufacturing. I discussed the importance of implementing an ongoing process monitoring program to not only achieve GMP compliance but also to manage quality risks effectively throughout the product life cycle. In this second part, we will look more deeply into how enhanced knowledge management can enable robust change management in the life sciences industry.
CPV Signals And Responses
Once a CPV program has been established, the next level of data-driven decision-making is developing the signal definitions and response rules. The goal is to establish a system to continually derive learnings to better understand and inform controls of the risks associated with production. In general, CPV signals are developed using statistical techniques sensitive to the size and inherent variability of existing process data to evaluate predicted performance.1 Even though CPV focuses primarily on relatively well-controlled processes, it’s still possible to detect variability in the process and associated quality attributes that may not have been evident when the process was characterized and introduced, which could be more than 10 years ago. Therefore, there needs to be a plan in place for escalation, whether to understand the cause or to be managed in the QMS.
For unexpected variations from historical processing experience, the first type of escalation is a technical evaluation to understand the cause of variance without a product quality impact assessment. Evaluations can go from a simple review of a batch record or starting raw materials to a complex, cross-functional evaluation, depending on the technical input of process SMEs. Some signals are significant enough to warrant a technical evaluation to assess potential product/validation impact and establish a root cause. This escalates the situation to QMS with a product/validation impact analysis, root cause identification, and CAPAs. Outliers, shifts, and drifts are classic CPV signals that have clear statistical rules. Taking into account process capabilities, comparing them to historical performance, and considering proximity to specifications, recurrence of similar signals, and multiple signals in the same lot can help determine whether to escalate. De-escalation could also be the outcome if related events are already investigated in QMS or are atypical variations related to planned studies.
All CPV protocols shall define the expected results and acceptance criteria clearly, which will allow for objective determination of pass/fail status of the observations and results, which shall also be documented. These clear-cut criteria can help articulate and explain impacts to those outside the quality function. It also helps with adoption of technology that could incorporate intelligent rules to carry out this long-term job. Below are two diagrams illustrating the application of a decision-making schema, adapted from the decision ladder of cognitive work analysis, to a complex CVP change decision (e.g., changes to a CPV execution plan for drug substance lifetime2). Situations for different complexity levels of decisions, and competencies required for different roles and responsibilities, can be added to this analysis before attempting to move onto a technology solution to automate these decisions.
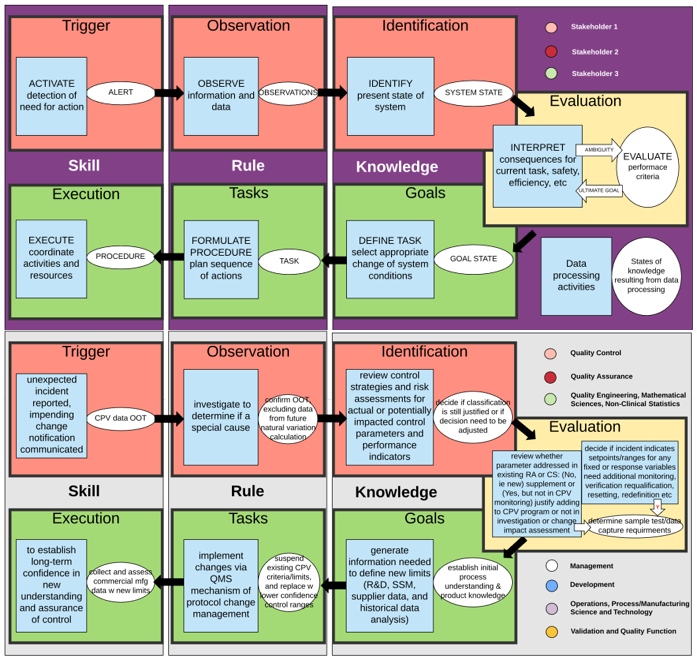
How Could Automation Help?
ICH Q12 provides recommendations for robust change management across multiple entities throughout the supply chain involved in the manufacture of a pharmaceutical product. An effective pharmaceutical quality system (PQS) as described in ICH Q10 and in compliance with regional GMPs is necessary for implementation of the principles mentioned in ICH Q12. Furthermore, automation is a top-level control strategy that can ultimately fulfill both patients’ and businesses’ needs for assuring product quality and enabling effective change management as described in ICH Q12.3 Ideally, the system captures meaningful stimuli, leverages the knowledge base to make data-driven, science- and risk-based decisions, follows clearly sensible procedures to implement and document changes, verifies effectiveness of changes, and passes on lessons learned for future references and that can even be utilized across similar products and/or sites. Some challenges exist, even as many organizations use electronic systems to track and manage change in isolated point solutions (i.e., only manage certain types of changes at certain locations), including limited visibility due to siloed data or information, operational inefficiency due to redundant change controls, disruption to production due to cumbersome process, and, at worst, compliance risk due to inconsistency across the organization.
Change management in the life sciences industry has both compliance and efficiency demands. On the compliance side, change control is a GMP requirement focusing on controlled management of change with proper criticality determination, approval steps, communication, and traceability to prevent unintended consequences. Change control aims to ensure that the safety, quality, purity, and potency of medicines are not compromised due to any changes in process or production. Therefore, an ideal change management solution includes a central repository of changes as a single source of truth, with a flexible configuration and integration with key systems and streamlined processes with an automated workflow that adopts a closed-loop approach. Whichever software solution a company adopts, there are three pillars of change management that go beyond the solution itself for adopting business process automation: (1) an IT function that handles changes, fixes, and upgrades of technology (infrastructure, system of record, etc.), (2) a business function that owns the process, defining requirements and overseeing change execution, and (3) organizational management for incentivizing, training, and engaging people.4 The groundwork lies in establishing a cross-functional collaboration mind-set that mines processes comprehensively, if not from end-to-end, to identify how humans and machines will be part of the workflow and how each will affect its counterpart. Having a broader understanding of the coordination helps the execution of change and development of solutions that align outcomes with stakeholders’ objectives.
Ontology Framework For Intelligent Data Analysis Example
Finally, here’s an example of the ontology or data framework behind an intelligent data analysis (IDA) of a sensor measurements approach.5 This can be part of a CPV program element for automatic data collection and some analysis using predetermined machine algorithms.
When it comes to knowledge management, taxonomy is probably a better-known concept — a hierarchical structure of terminologies used to represent a domain knowledge. Ontology uses those concepts, and relationships between those concepts beyond a hierarchical structure, as a common, explicit, and platform-independent agent to streamline the flow of information and knowledge generation. It is both “machine accessible” and “human usable.”
In this example, three ontology frameworks are connected to (1) capture quantitative raw data from the sensors and apply standard metadata, (2) semantically annotate the records of measurements (e.g., time instances, durations, temporal relations) using temporal modeling and reasoning, and (3) store and manage complex temporal abstractions involving qualitative representation of dynamic patterns defined by specific methods and actors. The collective practical application is using the multivariate modeling of temporal patterns to monitor the dynamic process in the plant and generate alerts as needed.
As in a typical data pipeline construction, implementation of an automated IDA process like this, which is part of a larger informatics system (e.g., electronic batch records, laboratory information management system), demands some questions to be answered pertaining to the following steps: (1) data capture (e.g., Are the source data systems validated? Does the data supporting the program span multiple data sources?), (2) data interface and query logic (e.g., Are the required interfaces off-the-shelf?), (3) data preparation and aggregation (e.g., Will the data preparation and aggregation functions be performed by the same or separate software systems as the analyses and report generating functions?), (4) analysis/reports (e.g., What are the user scenarios?), and (5) user interactions and user interface options (e.g., What are the definitions of testable design elements?).6
Conclusion
Continued process verification is often an overlooked part of the process validation stage. However, it serves as an important foundation and offers many opportunities to improve the usefulness of available relevant product and process knowledge. Enhanced knowledge management through the lens of CPV not only helps improve the regulatory impact assessment of a proposed post-approval change but also to bridge the gap to adopting a QbD approach to development and manufacturing, risk prioritization for internal changes, enabling a robust PQS, and continuous learning through data collection and analysis over the life cycle of a product. I hope you gained new ideas about orchestrating a program like CPV that could help each individual player in your organization better understand where they are in the grand scheme of things and how they relate to other parts of the picture.
Note: This article was based, in part, on a workshop presentation given by the author at the ISPE Annual Conference and Expo Oct. 17, 2019 (https://ispe.org/pharmaceutical-engineering/ispeak/pharma-quality-systems-regulatory-top-priorities-hot-topics).
References:
- S. Adhibhatta et al, “Continued Process Verification (CPV) Signal Responses in Biopharma”, ISPE Pharmaceutical Engineering (Jan/Feb 2017).
- BioPhorum Operations Group, Continued Process Verification: An Industry Position Paper With Example Plan (2014).
- Y. LX et al, “Understanding Pharmaceutical Quality by Design”, AAPS Journal 16(4) (2014).
- AI & Intelligent Automation Network, The IA Global Market Report 2019 (H1): How to Manage Change so that Automation Sticks.
- F. Rodaa and E. Musulin, “An ontology- based framework to support intelligent data analysis of sensor measurements”, Expert Systems with Applications 41 (2014).
- G. Gadea-Lopez et al, “Continued Process Verification and the Validation of Informatics Systems for Pharmaceutical Processing”, Pharmaceutical Online (2018).
About The Author:
 Peiyi Ko, Ph.D., CHFP, founder and principal consultant of KoCreation Design LLC, strives to help companies and teams set the foundation for innovative continuous improvements in operations and work environment. Since 2017, she has collaborated with industry professionals and written articles for Life Science Connect to research and promote integrated quality and adoption of technology by the life science industry. She has executed and managed projects, presented at conferences and university classes, as well as led workshops in various fields. Her approach to decision analysis, training design, and project communication is inspired by human-system interaction research and human-centered design. She obtained her Ph.D. from the University of California, Berkeley, where she also completed the Engineering, Business, and Sustainability certificate and the Management of Technology certificate programs in 2011. You can reach her at info@kocreationdesign.com.
Peiyi Ko, Ph.D., CHFP, founder and principal consultant of KoCreation Design LLC, strives to help companies and teams set the foundation for innovative continuous improvements in operations and work environment. Since 2017, she has collaborated with industry professionals and written articles for Life Science Connect to research and promote integrated quality and adoption of technology by the life science industry. She has executed and managed projects, presented at conferences and university classes, as well as led workshops in various fields. Her approach to decision analysis, training design, and project communication is inspired by human-system interaction research and human-centered design. She obtained her Ph.D. from the University of California, Berkeley, where she also completed the Engineering, Business, and Sustainability certificate and the Management of Technology certificate programs in 2011. You can reach her at info@kocreationdesign.com.